
Summary:
- Plagiarism detection includes intrinsic methods (analysing writing style) and extrinsic methods (comparing texts to databases).
- Existing software (e.g. Turnitin, SafeAssign) has limitations like false positives and struggles to detect semantic or cross-language plagiarism.
- Advanced methods involving fuzzy logic, semantic analysis, and swarm-based techniques are proposed to improve accuracy.
- Effective plagiarism management requires a combined approach of education, deterrence, intrinsic style analysis, and enhanced extrinsic semantic comparison tools.
This article originally published around 2014 remains highly relevant, particularly its detailed analysis of plagiarism detection methods. Although newer AI-based approaches have since emerged, the article’s core insights about limitations and the need for improved semantic detection continue to be significant.
Introduction
Definition of Plagiarism: To steal and pass off (the ideas or words of another) as one’s own: Use another’s production without crediting the source.1
Plagiarism Defined
The underlying argument in academia is that “plagiarism leads to the use of writings, ideas, innovations, etc. of others and reuse of them (partially or completely) without proper citation and reference to the source’.2 For educators, the capacity to identify plagiarism is constrained by the accessibility, quality, and functionality of the various tools and resources championed by institutional platforms. As a result, much of the research on plagiarism is based upon identifying and mitigating intention, a qualitative factor which has limited adaptability in analytical tools. For students, Dey and Sobhan argue that the decision to plagiarise is largely attributed to one of seven distinct conditions including a) lack of understanding about what constitutes plagiarism, b) belief that one’s own work is inadequate, c) poor writing/referencing/research practise, d) saving time/effort, e) getting higher marks, f) belief that majority of people plagiarise, g) cultural factors.3 The consequence of plagiarism on an institutional scale has been directly attributed to the degradation of institutional reputations, a persistent, negative impact on professional standards and qualifications, and even a negative impact on student values and academic practises.4 As a result of these outcomes, the need for exemplary plagiarism monitoring and detection has become unprecedented in today’s information-rich, globally connected scholastic community. For this reason, this study will explore a broad spectrum of detection techniques and strategies that have been developed in recent years as an intervention mechanism for higher education institutions (HEIs).
The taxonomy of plagiarism evolves out of the systematic identification of possible intra-textual manipulations. Alzahrani et al. offer an exemplary model that is largely based upon qualitative assessment of institutional findings during the review of student submissions.5 As evidenced in this visual model (Figure 1), there are two dominant cases of plagiarism, the literal and the intelligent. Literal plagiarism is tied to purposeful copying or manipulation of textual outputs either in whole or in part without providing due credit to the originator. Within the framework of literal plagiarism, plagiarists are unlikely to spend significant time attempting to “hide their academic crime’.6 Intelligent plagiarism, on the other hand, is much more difficult to detect and involves the manipulation of text, translation of foreign copy, or the adoption and ownership of others ideas, theories, or concepts. This form of plagiarism involves purposeful deception by students/academics and involves an attempt to obfuscate or change the original work in ways to prevent detection.7
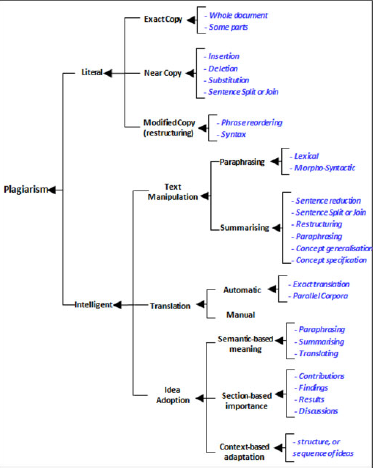
Figure 1: Taxonomy of Plagiarism8
The student-oriented deterrence and detection focus is an important component of the plagiarism epistemology, particularly as intra-classroom education and motivation is viewed as a primary measure of dissuasion.9 Reflecting on the core motivators for students to engage in this practise, Postle focuses on an outcome-based determination of student agenda setting, whereby high grades, degree-orientation, workload, deficient study skills/time management, and deficient understanding all increase the likelihood of engagement.10
One of the pitfalls of the plagiarism detection process evolves out of what Introna and Hayes refer to as the “socio-material imbrication’ phenomenon, or an institutional framing of assessment and monitoring as the defining factor in academic responsibility.11 For example, the researchers determined that in cases (UK and Greek) where Turnitin became the university standard for assessing and reporting on plagiarism, students and instructors alike evolved their concept of plagiarism to establish this proprietary framework as the founding authority on what plagiarism actually constitutes.12 In fact, in a more critical assessment of the Turnitin platform as a resource across the global academic community, Marsh referred to the “originality report’, or plagiarism summary as a “remediated material artefact’ which “transforms the context and circumstances’ which underlie the student writing and are inherent in the “originality’ of the draft itself.13 The problematic nature of this systematised manipulation of student work is that the concept of plagiarism itself becomes inherently attached to the assessment protocol, limiting the degree of flexibility and dynamism that is likely to be expressed in student writing.
Solutions relating to the mitigation of plagiarism in the classroom are largely tied to a “compelling’ force which inhibits the likelihood of student deviance. Compton and Pfau refers to more purposed, direct interventions as “inoculation treatment messages’ which are designed to “enable students to resist justifications for plagiarising’.14 Such arguments are based upon the rationality of plagiarism and the relative weight of counterarguments in student decision making.15 From awareness to student support, the degree of variance in plagiarism deterrence across the university landscape continues to undermine the value of such instructor-student communications. In fact, when attempting to justify the value of cloud based plagiarism detection services, McKeever cites multiple examples which both support and reject the introduction of Turnitin as a university standard.16 For students, “inoculation’ serves only as the springboard to prevention; it is ultimately a personal, ethical and moral decision that must be made in order to satisfy the terms of the HEI contract.
The Detection Mechanism
The detection of plagiarism is largely tied to systematic analysis of student submissions and is actioned either autonomously (e.g. through system automation) or administratively (e.g. instructor submissions). The black box concept of plagiarism detection involves an intermediary system which allows input documents (e.g. student submissions) and query documents (e.g. academic sources, online websites, databases, etc.) to be compared qualitatively to determine possible similarities.17 Extrinsic plagiarism detection is “a method of comparing a suspicious document against a set of course collection, whereby several text features are used’ to identify plagiarism.18 Intrinsic plagiarism is designed to identify the possibility of plagiarism, attempt to verify the authorship of the text in question, and potentially identify the real authorship of the text.19
The primary difference in intrinsic plagiarism detection is that the text in question is reviewed in isolation or is compared with a reference document (e.g. writing samples) in order to verify a correlation, or lack thereof, between the submission and the claim of authorship.
Although textual comparison remains the principle comparative tool amongst scanning mechanisms and applications, there are a variety of other emergent techniques that are being used to constrain the required search spectrum and efficiently analyse extra-cohort plagiarism. Document fingerprinting, for example, involves the comparison of documents in order to identify “gross similarities’, providing a comprehensive database outcome or “checksum’.20 Document tagging is more likely to apply to intra-cohort comparisons, whereby the principle document is “tagged’ via encoded data sets such as concealed identifiers which can be revealed when the content is transferred or copied to indicate plagiarism.21 Finally, there is a model termed “heuristic variations’ in which a table of general word frequencies is developed for both the object and the target documents in order to allow for matching of infrequently used words, punctuation usage, misspellings, or other distinctive indicators.22
Within the development of analytical tools, the expansive breadth of online source files and increased scope of student resources is continuing to complicate the detection capabilities of even the newest systems. Zhang and Chow propose a “coarse-to-fine’ framework solution for detecting plagiarism that is based upon a multilevel matching technique.23 This model employs a variety of data management techniques including the use of document-paragraph-sentence structure which defines the coarse-to-fine representation of each document, a signature matching analysis based on the length of sentences and histograms of the intra-textual terms, and a “pruning capability’ to enhance efficiency.24 Based upon the core principles of a distance algorithm, the histogram based retrieval function is designed to establish dissimilarity, efficiently eliminating a range of sources that are irrelevant when compared with the source document. Concurrently, two signatures for the source document are generated, one at the sentence and one at the document level, in order to establish a cross-textual similarity framework. The Zhang and Chow model25 is an important step forward towards a more comprehensive assessment resource; however, it is indicative of a purely quantitative, replication-based model, failing to address the complexities associated with semantic variability and intelligent plagiarism26 techniques.
With the popularity of particular detection platforms such as Turnitin and SafeAssign establishing a precedent for any future attempts at detection software or services, researchers such as Hill and Page offer a critical comparison in order to develop a more explicit taxonomy of features.27 For example, both Turnitin and SafeAssign employ a stand-alone or web-integrated interface that accepts virtually any text document and utilises a broad spectrum of internet web pages, academic databases, and their own proprietary database.28 Through the testing of 20 similar documents within each of these platforms, Hill and Page revealed that there was a significant degree of variance between the detection tools, with Turnitin achieving much higher detection rates than its counterpart, SafeAssign. Importantly, the variance in false positives was also significant in these outcomes, with Turnitin performing much better than SafeAssign. Regardless of platform, however, Hill and Page that the likelihood of false positives remains high in these processes, with more than 10% of all plagiarism detected erroneous and inaccurate due to system failures or “assumptive’ proofs.29
Deterrence and Detection: An Indiscriminate Opportunity
The primary limitation of anti-plagiarism search tools in today’s educational institution is that they are limited to the word-for-word analysis of intra-textual similarities, failing to address other important features such as conceptual adoption and presentation.3031 In fact, in order to address the likelihood of variability across university scholasticism, Youmans emphasised empirical findings that the detection of plagiarism is increased for both the complexity of the assignment (e.g. word count, depth of focus, level), and the topic in question (e.g. engineering versus humanities studies).32 The primary problem identified in such research is that there is a discrepancy between the expectation of universality in plagiarism report outcomes and the actuality of these findings when compared on a cross sectional basis according to the key factors in university scholarship (e.g. focus, level, project depth, project scope, etc.). Such findings were confirmed by Zeman et al. who revealed that in spite of student awareness regarding plagiarism software and detection objectives in the classroom, the originality of submitted works was not consistent, varying according to the focus, depth, or nature of the research in question.33 The failure to achieve consistent outputs through empirical testing of popular detection platforms is a clear indication that in their current state, the proprietary formulas and algorithms employed by these resources are inaccurate and unpredictable.
Another significant challenge in plagiarism detection is the degree of systemic variance across the broad spectrum of online services and exchanges currently used by universities. Samuel et al. argue that there is an explicit need for a much more lightweight integration of plagiarism checking software within university course management systems (CMS) in order to reduce the variability in intra and extra institutional outcomes.34 The variety of comprehensive solutions currently employed at academic or educational institutions include CrossCheck, TurnItIn, and MyDropBox, CopyCatch, PlagueDoctor, SNITCH, and YAP3, each of which Samuel et al. argue could be integrated within the Blackboard, ANGEL, or Moodle in order to improve efficiency in document checking and plagiarism identification.35 Yet with Turnitin establishing its global leadership across “80% of UK universities’ and an expanding spectrum of multinational HEIs, the authoritative benchmark set by this particular platform is continuing to influence and shape the core agenda of plagiarism monitoring and detection initiatives.36
In order to demonstrate the ingenuity in detection avoidance being employed by students, Heather addresses the core strategies employed in textual manipulation and output modification.37 Specifically, the researcher acknowledge that the first step in detection avoidance is to “stop the text from being properly extracted from the document, without affecting how the document looks and prints’.38 Within a PDF document, for example, a character map (CMap) represents all character codes and character identifiers unique to the document fonts, providing a blueprint for modifying and improving the appearance of printed text.39 To achieve a PDF file that looks and prints according to the text on the page but is artificially modified to swap character codes within the CMap, students are able to incorporate a custom CMap into the primary file linked to the OT1 encoding (ot1.cmap). The altered CMap manipulates the character code analysis to start at point 0062 (lowercase b) as opposed to the traditional 0061 (lowercase a).40
Alternatively, the student could alter or rearrange the glyphs in the font itself, whereby character code mapping fails to correspond to the normal alphabet.41 Programmes such as FontForge (open source software) allows the student to make a modified version of the standard font which switches some of the letters around. Students are able to identify specific parts of the document to be masked and then switch the font to reflect the modified output. Additionally, a general switch and replace function can be used to replace blocks of text with switched letters, still retaining the printing efficacy of the document, but evading detection by traditional plagiarism systems. One of the primary downfalls of this particular method is that the student must export the document as a .pdf because the modified font itself would not be accessible on any other user’s computer; this technique will retain the modifications, allow for traditional printing and reading, and ensure that the manipulated font is represented in the detection process.42 These particular subversion techniques are not comprehensive, resulting in a broad spectrum of detection avoidance approaches that can be used to reduce the likelihood of platform-based identification.
In response to such initiatives, Heather proposes that software providers have two primary solutions including attempts to spot rogue submissions and optical character recognition (OCR).43 Given that each of the aforementioned subversion techniques produce nonsense text, the system itself could identify various amounts of apparent nonsense and flag the document for manual testing.44 Alternatively, OCR can be used to convert the text via .PDF into a bitmap and then an OCR output, allowing the native text (not the manipulated scripts) to be passed through the scanner, eliminating the capacity for font or character-based modifications.45
The Detection Algorithm and its Evolution
Introduction
Although plagiarism detection has become a mainstream endeavour in academia, Introna and Hayes reflect that the proprietary nature of the scanning or analysis algorithm complicates the thorough dissection or analysis of systemic characteristics in today’s multivariate tech community.46 It is the nature of business-oriented system design that complicates any universal application of singular or distinctive scanning techniques, resulting in myriad dimensions and functions that are operating in a supra-institutional capacity. This chapter will offer a critical assessment of the key elements that are identifiable within the plagiarism detection algorithm in spite of the problems associated with inaccessibility and proprietary protections.
Detection Factors
For most educational institutions, the detection of plagiarism is tied to two distinct occurrences: the intra-corpal occurrence and the extra-corpal occurrence:47
Intra-Corpal Occurrence
- Mentioning as author of an article without contributing to it
- Submitting assignment as group work without contributing to it
Extra-Corpal Occurrence
- Downloading assignments from Internet, submit and claim as own work
- Buying assignment from private tutors, borrowing from friend, submitting as own work
- Copying one or more sections from a book or article without mentioning the source
- Translating and using an existing write-up without mentioning the source
- Using teaching/research material without mentioning the source.
Searching dynamics in plagiarism detection are one of the most complex concepts in algorithmic development and deployment. Ryu et al. reflect that “the plain text of a sequential file is hard to process (e.g. substring searching and comparison)’ therefore, a pre-processing technique must be used in order to assess the input plain text.48 Within such analyses, the researchers argue that document plagiarism is characterised by both spatial similarity and temporal coherence; therefore, similarity in these factors equates to an outcome of identified plagiarism. Within these relationships, Ryu et al. propose that there are several explicit definitions, whereby similarities and differences define the relative determinations:49
- For two different documents
 the Spatial Similarity
the Spatial Similarity  is identical to the asymmetric document similarity
is identical to the asymmetric document similarity  </
</
From this particular formula and the variable inputs described by Ryu et al., it becomes possible to address the relative similarity in plagiarism which reflects both temporal and spatial interlocution across these two distinct texts.50 Through such outcomes, the evidence pioneers what is known as the “Evolutionary Plagiarism Probability’ (EPP) function,51 focusing on algorithmic relationships that may ultimately serve as a deterministic resource in the broad scale assessment of plagiarism in academia and the online community. Introna and Hayes extend this model further to reflect a common concept termed “winnowing’, or the comparison of a source-based “digital fingerprint’ of the original document with a variety of other sources. This process involves four primary steps which include “the removal of irrelevant information from the text (white space and punctuation) to create a continuous character string; chunking this text into equal blocks (of x characters); converting these chunks into numerical values (hash function); and finally taking a sample of consecutive hashes from the string of all the hashes to store as the digital fingerprint’.52 Given the management of the footprint dataset, the likelihood of variability amongst scanners is significant, resulting in output inconsistencies due to inconsistent densities, hash placement, and fragment management techniques. Even more importantly, Introna and Hayes caution that students are able to manipulate the character sequence by rewriting the sourced text in way that detection by this method becomes unlikely.53
The plagiarism detection algorithm requires several distinctive components in order to ensure that it is consistent across document search and analysis parameters. For example, Zini et al. introduce a formula for defining structural similarity in which chunk elements of two documents are equal to 1 minus an edit distance between the two chunks divided by the maximum of the sub-chunks (node of level to document tree) of each document.54 The underlying concept associated with this calculation is relatively simple, as the output represents a measure of similarity that is based upon the quantitative determination of textual features (e.g. words and relationships within the thematic tree).55 For the authors, the closer that a document is to receiving the score of 1, the more likely that there is some form of plagiarism, establishing a numeric scoring protocol that can serve to highlight the possibility of both content and word similarities. On the other hand, the model is ostensibly limited by the scope of comparative outcomes whereby a 1 to 1 assessment is far from representative of the much broader complexity of today’s academic environment.
It is the resolution of the search query function that ultimately allows the detection industry to progress forwards towards a more tangible industry benchmark. Butakov and Shcherbinin introduced the concept of a sliding window approach which assesses a sequence of words from within the text against search engine results from internet search providers such as Microsoft Live Search.56 Contrarian arguments in this field offered by Knight et al. suggest that the use of the sliding window approach to this form of query could lead to an increased number of queries and decrease the overall efficiency of the detection process.57 Butakov and Shcherbinin reject this concern and instead suggest that by employing a random selection search methodology, search queries can be reduced and the time to comparison can be greatly reduced.58 By prescribing a window of 7 words, a sequence of words was identified in the beginning of the document that could then be introduced into the search engine. Utilising purposefully plagiarised texts, the researchers revealed that even when using just a small number of the search queries (5%), the plagiarised texts were identifiable within the first series of search results.59 The results are an important step forward in the definitions associated with intra-textual detection methodologies, as a sliding window assessment tool could significantly improve system performance and search efficiency if controlled for superfluous data.
Ultimately, the detection of plagiarism is reliant upon a measure of similarity, which Sanchez-Vega et al. suggest remains vulnerable to “false positives’ due to the potential for word-based overlap in the output of the detection tool.60 Yet the underlying, and unspoken agenda reflected in such research is tied to intention, a factor which ultimately precludes the assumption of flagrant plagiarism. Given that “common word sequences between the suspicious and source documents’ are regularly identified as the primary indication of plagiarism, any programme recording a positive correlation might unknowingly be reporting a false positive in its place.61 To resolve this unreliability, Sanchez-Vega et al. developed a more intuitive algorithm which is based upon both narrow and broad similarities in textual comparisons, ultimately recording the rewriting the degree, the relevance, and the fragmentation features in the output.62 Most importantly, such research establishes protocol for modelling both verbatim (similar) and manipulated (possible) word replications, identifying a broader spectrum of plagiarised texts and concepts by increasing the complexity of the classification algorithms used for the assessment.63
Semantic Similarity and Intrinsic Detection
By definition, semantic plagiarism is more complex than “cut and paste’ efforts, wherein unique ideas are integrated from sources into a student’s own work.64 Building upon the concept of textual summarisation championed by Alzhahrani et al65, Kent and Salim propose that the fuzzy swarm approach to key text comparison of sentence similarity offers a unique mechanism for detecting semantic similarity and narrowing the scope of evidence used for determining plagiarism. An essential component of this model is the ability to distinguish between two examples of student work via intrinsic detection. Li et al. developed a specific methodology in which word similarity and order similarity are compared utilising word vectors from two chosen pairs of sentences.66 Such modelling is based upon matrix operations and singular value decomposition (SVD), whereby it is possible to introduce scaling controls in order to limit the breadth of semantic analysis. Specifically, words that operate within the higher layers of the “hierarchical semantic net’ have less similarity between words than those at lower layers, whereby the calculations themselves are applied to a monotonically increasing function to accurately define the depth of the search process.67
The most progressive inclusion in the Li et al. semantic analysis model is the incorporation of a Princeton University database called WordNet. The database is defined as a “large lexical database of English in which nouns, verbs, adjectives, and adverbs are grouped into sets of cognitive synonyms, each expressing a distinct concept’.68 These synsets (cognitive synonyms) are distributed in WordNet according to a hierarchical structure in which language features are grouped according to their progressively specific relationship, allowing for a pathway between the words across the lexical tree.69 This lexical knowledge base mirrors human understanding of words in natural language usage and allows for modelling semantic similarity across the intra-textual inputs.70 The output of this analytical process is a word order and sentence order threshold assessment, whereby plagiarism is statistically measured and its likelihood can be defined according to a percentage basis.
The applicability of the SVD analysis in plagiarism evolves out of a vector based mapping protocol traditionally reserved for geographic, climatologic, and other complex technical problems.71 To test the value of this protocol, Ceska conducted a systematic assessment of documents, applying six different stages which ultimately result in a normalised, summative output of plagiarised similarities. These six stages can be explicated as follows72:
- Text Pre-Processing: Based on natural language processing (NLP) tasks, stop-word removal (removal of all common/inconvenient words from text) and lemmatization (process of determining the lemma (e.g. context, part of speech) for a given word) is applied to the source document
- Phrase Extraction: Retrieves simple ideas from the text, specifically the word N-grams of a specified length from pre-processed text (1-5 words). Note: the accuracy of method decreases as quickly as the length of the N-grams increases.
- Phrase Analysis and Reduction: Document frequency (DF) feature selection protocol which allows for phrases existing in just one document to be removed right away. Also eliminates common phrases contained in more than
 , where
, where  is the mean document frequency and
is the mean document frequency and 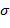 is the standard deviation from the mean document frequency.</
is the standard deviation from the mean document frequency.</ - Building a Document Model: Phrase by document model which considers occurrence frequencies of phrases in the documents, whereby relationships can be depicted in matrix form.
- Latent Semantic Analysis: Infer latent semantic associations among phrases in the documents. SVD is employed to decompose the initial matrix into three independent matrices. All matrices are then decomposed in a reduced latent space.
- Document Similarity Normalization: Compute mutual pairwise document similarity. Correlation calculations are performed to identify possible intersections and similarity is graphically modelled.
The Ceska SVD model is an important step forward in addressing the high degree of semantic variability associated with student work and the potentiality for intrinsic, strategic manipulations of the source document. In a more recent semantic analysis model presented by Ceglarek and Haniewicz, the primary objective in dissection and compression is to identify passages of similar but altered text that was “borrowed’ from an original document.73 The researchers leverage a sentence hashing technique which serves to normalise the text according to the number of sentences separated by a full stop.74 Further dissection in the hashing process involves the division of sentences into text frames, whereby each term in the frame is mapped onto a unique term and a value for the frame is computed based upon the sum of numbers representing the terms.75 One of the primary challenges of this particular approach, however, is determining the appropriate length of the text frame, a factor which Ceglarek and Haniewicz suggest is relative to the language and domain of the document in question.76 When the assessment algorithm is then applied to this hashing sequence, key matches are detected and the frame numbers are updated to reflect the degree of matching across the frame sequence. Given that this particular approach was originally rejected due to the length of processing time required, similar to the normalisation techniques employed in Ceska, the Ceglarek and Haniewicz introduction of sentence hashing is an important step forward in pre-processing and system efficiency achievements.
Whilst many of the semantic plagiarism resources are geared towards the comprehensive assessment of essays and dissertations, the increase popularity and prevalence of e-homework and e-classwork suites is resulting in a more advanced protocol that can offer detection value within various document and textual classes. Xiaoping et al. build upon the Samuel et al.77 model of dashboard-based e-plagiarism detection in order to develop a revised platform based upon the vector space model (VSM).78 In fact the protocol operates as a gateway resource for instructors, rejecting texts that are identified as plagiarised or containing a degree of plagiarism that exceeds the system threshold. The module-based architecture is composed of the CMS upload queue, a plagiarism detection module, and the detection result management module, significantly reducing the work or responsibility required of the e-classroom instructors.79
Alternative Models and Algorithm Targeting
The tree-based structure model of plagiarism detection is becoming an important foundation in semantic text recognition and intrinsic plagiarism detection. Expanding beyond the limitation of database sourcing, Tschuggnall and Specht focus on detecting plagiarism without using a reference corpus by processing and analysing the grammar of the document in question. Although Dey and Sobhan differentiate between intra and extra corporal plagiarism80, Tschuggnall and Specht reflect that in detection protocols, external detection algorithms compare a suspicious document with a set of source documents, whilst intrinsic detection algorithms try to find sections by inspecting the suspicious document only.81 Within the field of intrinsic detection, grammatical analysis algorithms such as n-grams or word frequency models are largely based upon the assumption of authoring and sentence structure similarities.82 As an alternative to these previously tested techniques, Tschuggnall and Specht propose a new “plag-inn’ algorithm which utilizes sentence boundary detection to identify the beginning and ending of sentences, a comparison of the grammatical structure according to a tree-based model, and a calculation of distance between each grammar tree.83 The technique is unique, as it generates both visual and quantitative evidence of variations in the authoring of a particular text, limiting the need for any additional external resources in the initial plagiarism assessment process.
Extending the Tschuggnal and Specht corpus-free, intrinsic plagiarism detection model, Myer zu Eissen and Stein based their detection techniques on the evolution of plagiarism taxonomy towards a stylistic analysis.84 In order to effectively quantify the “natural parts’ of an author’s unique writing style, the researchers proposed an assessment of several key features as follows85:
- Stylometric Features: Quantify aspects of the writing style according to five primary categories including text statistics, syntactic features, part-of-speech features, closed-class word sets (special words), and structural features.
- Averaged Word Frequency Class: Frequency class of a word is directly connected to Zipf’s law and is used as an indicator of a word’s customariness. This classification bases the frequency of word usage according to the overall model of the text corpus based upon class-based customariness.
Acknowledging the lack of an adequate “reference collection’ for this particular experiment, Myer zu Eissen and Stein developed a new corpus based upon four corpus linguistic criteria including authenticity and homogeneity, possibility of types of plagiarism, processable for human and machine, and clear separation of text and annotations’.86 The assessment process involved the creation of 450 documents (from published sources) with 3-6 plagiarized passages in each, that were decomposed into 50-100 unique passages from which the feature vectors were computed.87 The outputs of this particular study were extremely limited; however, it is clear from the three primary factors (frequency, preposition number, and sentence length), that it is statistically possible to identify changes in writer voice through the assessment of grammatical elements.
Recognising a breadth of deficiencies in existing detection models, Sandhya and Chitrakala propose an alternative document retrieval and plagiarism detection system which employs a non-traditional technique entitled the “multi-layer self-organizing map’ (MLSOM).88 This particular system utilises a clustering algorithm to represent comparative documents in a tree structure which is extracted by partitioning the document into pages and paragraphs.89 Focusing on “type synonymy’, the researchers attempt to identify similarities across the paragraphs in the multiple documents, wherein semantic similarity computations are performed on a word by word basis.90 Importantly, the tree structure employed in this particular model involves a layer loop analysis in which the MLSOM algorithm extracts and delimits paragraphs, conducts a word by word assessment, and identifies both exact and paraphrase linkages. The Sadhya and Chitrakala research is an important step forward in the automation of plagiarism detection, particular when attempting to reconcile one of the most serious disadvantages of these electronic systems: the nature of semantic variability and breadth of student-based linguistic manipulation.
Emergent External Plagiarism Detection Models
One of the most significant challenges in external plagiarism detection is the breadth of the corpus data that is set as the input for analytical systems. Micol et al. reflect that in order to reconcile the scope of information management associated with such complexities, programmes are now incorporating natural language processing (NLP) to determine whether intra-textual approximations and similarities can be more easily (less cost, less time consuming) identified.91 Within such pre-processing techniques, corpus filtering is an important stage which allows systems to minimise the scope of analysis and irrelevant document scanning. To accommodate such processes, Micol et al. propose two different methods of corpus filtering including a full text search engine which indexes and filters the database, and a document similarity measure which compares semantic information through grammatical expansion in order to detect obfuscation.92 Through a critical comparison of these two distinct methodologies, the researchers determined that the full text search engine method was less proficient in its parsing methods, requiring a much smaller assessment set. Whilst the performance outcomes in relation to plagiarism detection were similar, the findings reveal that there is potential for extrinsic detection methods that employ similarity and semantic analysis modules.93
By definition, Oberreuter et al. suggest that external plagiarism involves the comparison of suspicious documents with a set of possible references; however, the parameters of deviation and foundations of detection continue to vary according to external platform.94 Accordingly, the researcher propose a more systematic approach to detection strategies which employs the n-gram technique for narrowing the search space within the external corpus.95 Focusing on the link between intrinsic and extrinsic detection techniques, Oberreuter et al. cite an intrinsic n-gram profiling technique which focuses on quantifying style variation according to dissimilarity measures throughout the text in question.96 Building upon the work of Stamatos, such intrinsic assessment protocol is designed to identify and quantify variations in the writer’s style, allowing reviewers to systematically determine whether there is a high likelihood of plagiarism.97 On the external side of this analysis, Oberreuter et al. contribute to the intrinsic detection methodology by modelling the closeness of documents using a distance-based outlier detection approach applied to an academic corpus.98 Such research highlights the comprehensive nature which more evolutionary platforms are pursuing in their incorporation of both intrinsic and extrinsic analysis methodologies.
Authorship and intra-textual comparisons continue to operate at the root of plagiarism detection models; however, Suzuki argue that rather than prioritising grammatical or voice-based stylisation, there are other indicators that should be considered in such approaches.99 Specifically, the researchers identify morphemes (network indicators) and co-occurrence based concentration indicators for authorship analysis. Within these particular indicators, there four particular characteristics including frequency of morphemes, basic indicators, network indicators, and co-occurrence based indicators, which are based upon lexical and morphological similarities between the target and the source texts.100 Supplementing more conventional lexical indicators, the researchers argue that this new technique has extended value for authorship profiling and computational sociolinguistics, allowing for a clear definition of the author’s profile and character that is based solely on the characteristics of the texts.101 The research itself is oriented towards a much broader spectrum of assessment than simply plagiarism detection; however, the findings offer a valuable insight into ways in which cross-comparison of grammatical and lexical fingerprints can serve as an intermediate detection platform for expediting the plagiarism analysis process.
Fuzzy Models and Language Processing
Recognising that paraphrasing or internal textual manipulation is continuing to avoid detection due to the inconsistent nature of the document fingerprints, Osman et al. suggest that a more immersive technique is needed based upon fuzzy logic and semantic role labelling (SLR).102 SLR involves the division of text into similar segments according to sentences, words, or topics, the deletion of meaningless words, and the introduction of a stemming algorithm to eliminate prefixes and generate the root word.103 Once the SLR framing has completed, Osman et al. identified an if-then rule which utilises an “and’ operator to constrain the scope of the relationships, redirecting all possible rules into a singular equation104:
- IF (Similarity score of argument x in Sentence 1 is Important) and (Similarity score of argument x in Sentence 2 is Important) and (Similarity score of argument x in Sentence 3 is Important) and (Similarity score of argument x in Sentence 4 is Important) and (Similarity score of argument x in Sentence 5 is Important) THEN (argument x is Important).
Applying these fuzzy rules and SLR decoding to over 1,000 documents, the researchers suggested that when applied to a traditional PAN-PC-09 standard dataset for plagiarism detection, this modified fuzzy rule-set had significantly improved performance over less comprehensive semantic based string similarity, graph based, and SLR-argument weight methods.105 In spite of such findings, it is evident that the Osman et al. methodology is simply an interwoven manipulation of an evolving foundation for semantic plagiarism detection which incorporates SLR and weighting protocols in order to effectively distinguish between meaningful and non-meaningful textual manipulations.
Interconnectivity, semantic similarities, and epistemological mirroring are characteristics of intrinsic plagiarism which continue to prove difficult for traditional platforms to detect. Foudeh and Salim contribute a new “probabilistic ontology’ method which involves the use of both traditional (database-driven) and experimental (reasoning and quantitative probability analysis) techniques.106 The experimental reasoning engine employed in this particular model is problematic and identifies similar relational challenges to those highlighted in the Osman et al model. In fact, Foudeh and Salim, unable to adequately reconcile the challenges of criteria setting and similarity rule making, argue that a more comprehensive training set is needed in order to effectively define accurate, consistent probabilistic threshold values.107 From more intuitive analytical factors such as a reference-based linking analysis to epistemological reasoning assessment and comparison, these probabilistic models are designed to evolve over time, maximising the utility of their capacity for similarity analysis and plagiarism determination.
Fingerprinting and Student Identification
Whilst many of the incidences of plagiarism identified in academic institutions are tied to an extra corpal108/cohort109 outcome, the intra-corpal/cohort outcome (e.g. copying from a classmate’s essay) presents a unique concern for educators as classroom sizes and institutional flexibility (e.g. online courses) are continuing to advance. The fingerprinting, document-tagging approach proposed by Weir et al. attempts to eliminate the potential for intra-textual exchange within classroom settings by prescribing explicit document tags for each student.110 This protocol, although potentially vulnerable (e.g. hacking, document manipulation, backdoor access, etc.) serves as a front line control mechanism for student activities. Importantly, Weir et al. propose that if any part of a student’s document is shared with their classmates, those underlying tags will also transfer, providing an immediate flag to indicate plagiarism as instructors begin their reviewing process.111 The primary limitation of such a text-to-text control structure is that it fails to address the more likely outcome of any student sharing practises in higher institutions: a summative, manipulative textual adoption that bypasses copying and word for word replication.
Game Series and Automated Plagiarism Detection
In order to facilitate the learning objectives of any degree level course, a range of assignments or examinations are prescribed via syllabus for the student population. Recognising the opportunities afforded in today’s game-oriented, online-experienced society, Graven and MacKinnon reflect that there is significant potential to fundamentally revise the classwork schedule in order to not only maximise the utility of the education process, but to mitigate the potential for student plagiarism.112 This particular strategy involves the use of an automated, in-system scanning tool which incorporates the Turn-It-In module as the primary mode of comparison. On the basis of empirical findings, Graven and MacKinnon argue that for more unsophisticated plagiarism, the system itself is a valuable addition to electronic learning; however, due to inadequate richness and fuzziness, it becomes much more difficult to detect robust, content-based response manipulation.113
Cross Language/Multi-Lingual Plagiarism: The New Obfuscation
Recognised as cross-language or translated plagiarism, Alzahrani et al. define this process as the translating and manipulating of a “natural language text from one language into another without proper referencing to the original source’.114 Based upon a summative, keyword search process, the evolution of a fuzzy, swarm-based platform for analysing academic sources across multiple language is a marked step forward in this field. The underlying strategies associated with the Alzhahrani et al. system design include the summary of the text in question, the identification of native language keywords, a system crawl of resources in other languages with similar keywords, and finally, a detailed dictionary-based analysis of the original text versus the various search results.115 This particular approach emphasises a unique contribution to the field of plagiarism scanning in the form of summarisation modelling of native and foreign textual vocabulary. Further, the fuzzy swarm based analytical technique is an extremely forward-thinking methodology for analysing and identifying textual patterns and keywords in order to reduce the bandwidth and scope of intra-textual searching and review.
In order to develop this pioneering method, Alzahrani et al. identified five key sentence features that are used to score the various sentences throughout the native language text including sentence centrality, title feature, word sentence score, top word feature, and first sentence similarity.116 One of the key tools required for the translation approach to the search-based analysis of foreign language tests is the Google AJAX Language API. As of April 20th, 2012, Google had redefined this translation protocol as Google Translate API and offered a paid service which varies according to the millions of characters that are translated.117 One of the key values of the Google translate service is that it is accessible in multiple programming languages ranging from Ruby to Java to Python, allowing software developers to adapt a third party translation protocol that can be integrated into multiple online platforms.118 Once translated summaries have been compared across the breadth of foreign language resources featuring a keyword similarity outcome, the Alzahrani et al. model provides users with a similarity record that allows for threshold outcomes to reflect the likelihood of plagiarism and enables further in-depth document assessment by third party analysts (educators, adjudicators, etc.).119
Reflecting upon the multidimensionality of plagiarism, particularly in the context of English (L2) scholars, Pecorari defines the concept of “patchwriting’, which represents a holistic union between writer and source that is the direct result of a lack of competence and linguistic proficiency, rather than a purposeful incident of plagiarism.120 In fact, Stapleton suggests that there may be a direct bias in the frequency of plagiarism towards L2 students (when compared with English native speakers) due to both linguistic and attitudinal forces.121 Importantly, it is the relative bias of the output scoring mechanisms (e.g. the originality report for Turnitin) which Stapleton suggests may falsely identify correlations in textual constructions, particularly when assessing non-native English speakers.122 On the other hand, there is evidence to suggest that the influence of a formal checking mechanism may have a positive impact on the frequency of plagiarism, particularly when applied with concurrent explanatory supports from the classroom instructor.123 In spite of the important questions raised in the Stapleton study, it is evident that generalisation and assumptions in plagiarism monitoring are continuing to perpetuate inconsistencies, mitigating the potential for more prescriptive solutions.
Given that the principle of obfuscation in multilingual plagiarism is based upon the manipulation of multiple linguistic dimensions (e.g. grammatical, semantic, structural), Ceska et al. propose that more universal mechanisms can be developed in order to limit the likelihood of scanner oversights.124 Specifically, the researchers developed a multilingual database for multiple European languages that compares synsets (synonyms) and interconnects languages through an inter-lingual index.125 Classified as a dictionary lemmitization method, the researchers propose that by developing a sufficient database of corresponding lemma within the euro-word-net thesaurus, pre-processing can significantly improve the capacity for cross-lingual plagiarism detection.126 The empirical tests represent a unique breadth of multilingual assessment, whereby the linguistic factor is constrained in its potential for obscuring the detectability of translation-based copying; however, the research itself is indicative of a clear challenge in such model development: the complexity and depth of the database required for adequate assessment. In fact, the Ceska et al. model is just one step forward in such processing technologies, failing to develop a sufficiently populated global thesaurus, whilst simultaneously demonstrating the viability which such techniques have in multilingual assessment.
From Plagiarism Detection to Socio-Cultural Stereotyping, the New Debate
Whilst detecting multilingual plagiarism may represent a new dimension in assessment and analysis, there is a robust, emergent debate today in academia regarding cultural stereotyping and the prevalence of plagiarism amongst ESL and overseas students. Sowden, for example, began with the cultural underpinnings of plagiarism and the concept of “communal ownership’, a potentially problematic dimension of socio-cultural diversity.127 Citing evidence from students in various cultures, Sowden identified incidences of plagiarism in which students found their behaviour inherently appropriate considering the tribute which it paid to their instructors, tutors, and sources.128 Yet in spite of a range of examples, Sowden also cautions against stereotyping multilingual students, suggesting that instead, students should be universally encouraged to meet a similar standard, pursuing originality, yet anticipating conceptual mirroring and similarity by virtue of the topics and subjects that are being researched.129
Other researchers take a less amenable position than Sowden in relation to the nature of stereotyping and educational concerns regarding foreign or EFL students. For example, Ha, reflects that whilst many Western instructors are quick to stereotype foreign students as inherently poor scholars or poor writers, the degree of commitment to writing education across their multiple primary institutions has remained extremely variable.130 Further, Ha suggests that many institutions fail to take the time to consider the influence which culture, language, and identity have on student writing, attempting to prescribe more localised cultural values instead of addressing the root core of the problem: variability in education and cultural development.131 Citing the Sowden and Ha positions, Liu counters that to prescribe an inherently “culturally conditioned’ stereotype to any foreign student is to fail to address the pedagogical implications of plagiarism and to constrain any actual solution-oriented systems.132 From language and writing development to in-classroom guidance and support, Liu argues that rather than “dwelling on issues that have few direct pedagogical implications’, it is imperative to focus on appropriate solutions that are oriented towards overcoming the problem, rather than excusing it.133
3: Fuzzy Sets and Swarm-Based Comparisons
Introduction
The following chapter offers a review of the emergent research associated with fuzzy logic and swarm-based technologies. An emergent field in linguistic and textual analysis and summarisation, these techniques are only just now being applied to problems of plagiarism and corpus-based comparisons. Given that plagiarism itself is becoming more complex, oftentimes involving translation-based subterfuge, there is a distinct need for methodologies which are able to reconcile the contextual, conceptual, and semantic dimensions of similarity within a comparative framework. These studies can be viewed as a positive step forward towards a resolution of the quantitative and qualitative relationships within academic documents.
Fuzzy Plagiarism Detection, Translation, Semantics, and Linguistic Variables
Citing an evolution of plagiarism detection techniques, Kent and Salim recognise that whilst the majority of early stage detection systems were based upon fingerprint matching, they have since been joined by evolved models utilising advanced clustering techniques or sylometry measurement and comparison.134 Based upon translation modelling and the distillation of the source text through pre-processing techniques such as stop word removal and stemming, Kent and Salim propose that even translated texts can be traced back to their original source through more comprehensive detail comparison and taxonomy assessment.135 Advancing this analytical resource towards a more effective, fuzzy swarm model, the researchers propose that particle swarm optimisation can be used to assess five key features across the intra-textual content including sentence centrality, key word feature, first sentence similarity, title feature, and word sentence score.136 This swarm intelligence model is integrated into the fuzzy logic algorithm in order to develop a summarization output. Specifically, the explicit, “crisp’ numerical values obtained during the five sentence swarm assessment are then used as the input for the fuzzification process, resulting in a value output between 0 and 1, and a scalar interpretation of low, medium, and high correlation.137 Given the complexity of in-sentence relationships, Kent and Salim propose the use of more than 200 If-Then fuzzy rules such as the following:138
IF (WSS is L) and (SC is L) and (S_FD is M) and (SS_NG is L) and (KWRD is L) then (output is unimportant), whereby each acronym stands for one of the five scores in the swarm intelligence analysis.
Once these rules have been applied to the source text, each sentence is given a score that is based upon the fuzzy inference system and a final summary is obtained that is “based on the top-n highest score sentences where n is the compression rates of the documents which are determined by the users’.139 The most important contribution of the Kent and Salim research, however, is not necessarily the design of the fuzzy model; instead, it is the pursuit of plagiarism detection for both translated and semantically similar texts.140 Specifically, a similarity index between the predicates in the documents is calculated, whereby a synthesis of all possible predicate combinations from each sentence is generated and then compared across the corpus of potential documents.141 The output is then based upon the detection of similarity between the object and subject in the sentences through semantic comparison, allowing analysts to identify plagiarism regardless of structural manipulations.142
Within the concept of fuzzy (linguistic) data analysis, Kaburlasos et al. propose that a graph matching protocol using neural networks can be used in object recognition in order to reflect the similarity or best match output between an input “graph’ and a stored “graph’.143 Although the researchers apply this analytical protocol to various hypothetical “graphing’ inputs, the relevance of the fuzzy lattice function for identifying similarity and consistency between textual outputs is significant. Specifically, the researchers define a fuzzy set as a paired function which includes U as a universe of discourse and m as a membership function, allowing for the assessment of similarity space and equivalence relation output.144 Extending such techniques to the field of linguistic processing, Alguilev et al. propose that similarity measures operate at the core of natural language processing, whereby the similarity between texts can be classified into four primary categories including word co-occurrence/vector-based methods, corpus-based methods, hybrid methods, and descriptive-feature-based methods.145 Given that each document in question is likely to reflect a diverse spectrum of information which may or may not be manipulated towards a masking purpose, Alguilev et al. propose that effective summarisation methods are able to extract core evidence and compare these outputs with other similar, target documents in order to highlight redundancies and similarity-based relationships.146
Text Summarisation and Fuzzy Swarm Techniques for Plagiarism Detection
Other researchers in this field have also proposed mechanisms for text analysis and data parsing through the use of a fuzzy swarm tool. Binwahlan et al., for example, propose that automatic text summarisation offers an opportunity to “condense the source text by extracting its most important content that meet’s a user’s or application’s needs’.147 Within the document itself, the diversity-based selection process controls for redundancy through maximal marginal relevance calculations, wherein the centrality involves the summation of three features including the similarity between the sentence in hand and each document sentence, shared friends (the group of sentences which are similar to both sentences) and shared n-grams (group of n-grams which are contained in both sentences).148 Procedurally, the Binwahlan et al. methodology involves the input document, pre-processing, features extraction, sentence clustering and binary tree building, sentence order in binary tree, and summary generation.149 When applied to the document, the swarm-based summarisation is used to select the top sentences which have the highest scores according to sentence centrality, the title feature, the word sentence score, the key word feature, and the similarity to the first sentence.150 Figure 2 offers a stepwise model of the assessment process, incorporating both features and swarm-based sentence analysis into a singular diversity-based summarisation output.
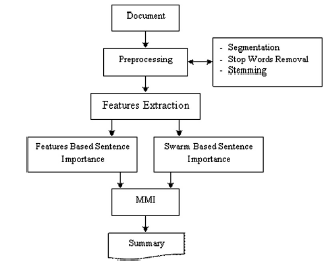
Figure 2: MMI Diversity-Based Text Summarisation and Swarm-Based Text Summarisation
Extending beyond the traditional scope of the MMI summarisation model, Binwahlan et al. propose the use of a hybrid model which includes the diversity based method, the fuzzy swarm based method, and a combination of swarm-diversity method and a swarm-only method.151 The resultant, combinative model is exemplified in Figure 3, highlighting three tiered features analysis process which results in three distinct summaries that are then input into the selector procedure and result in a final, summative output based upon textual importance152. Whilst this model itself is designed for large scale text analysis (e.g. legal briefs), the relevance of these techniques to the identification of internal plagiarism is significant and reflects a unique opportunity to establish similarity dimensions that are content-derived and semantically based.

Figure 3: Fuzzy Swarm Diversity Hybrid Model for Automatic Text Summarization
Within the dimensions of text summarisation technologies, Alguliev et al. emphasise that there are four distinct classifications of the textual output including descriptive, evaluative, indicative, and informative.153 Most relevant to the current study, the evaluative output represents a critical response to the source, allowing for summative elements to be compared or assessed according to some control variable(s). Within this model, multi-document summarisation allows for multiple texts to be summarised simultaneously, clustering outputs and allowing for knowledge synthesis or discovery.154 The proposed Alguliev et al. text summarisation model involves a core problem of assessing a given textual input in order to reproduce the primary content in a summative form according to three core factors including relevance, redundancy, and length.155 Based upon the quantitative assessment of similarity throughout the input text, the researchers utilise a branch-and-bound algorithm to find the optimal solution (hard problem) and incorporate a particle swarm optimisation algorithm to parse and select the fitness of each intra-textual element. This particular methodology involves comparison of each particle according to its position in the continuous n dimensional search space, whereby the best previous position and the velocity are recorded and analysed according to an iterative global best.156 Whilst the Alguliev output is an original, summative document, the particle swarm methodology is validated as an effective assessment for relevance, redundancy, and length in textual comparisons, a finding which has particular implications for plagiarism assessment.
Symbolic data, such as linguistic outputs, represents a complex and oftentimes dissociated spectrum of elements and dimensions which Yang et al. propose can be critically assessed through the use of neural networks and self-organising maps (SOM).157 Specifically, the SOM “uses the neighbourhood interaction set to approximate lateral neural interaction and discover the topological structures hidden within the data’.158 Symbolic data types differ from numerical evidence; therefore, Yang et al. apply a dissimilarity/similarity measure in order to distinguish between component features.159 Within this complex interweaving of algorithmic relationships, the researchers strive to extend the SOM beyond purely quantitative definitions, applying the symbolic relationship to allow for the analysis of distance measures and dissimilarity factors in membership-based comparisons.160 Whilst the specific foundations of this research are based upon social clustering problems, the relevance of such advanced neural networking techniques to plagiarism detection is evident and would likely serve as a unique step forward towards resolving both semantic and corpus based dilemmas.</p >
Summary
The methods introduced in this chapter employ an advanced, multi-dimensional technique which is based upon the concepts of fuzzy sets, swarm modelling, and neural networks. Considering that knowledge itself is self-organising, the ability to conceptually and contextually cluster inter-textual characteristics across singular and corpus-based documents is a unique advantage for identifying similarities in plagiarism detection. The textual summarisation models establish a synthetic foundation for semantic and contextual comparisons, whereby conditions of plagiarism can be explicitly outlined. Whilst all of these models have yet to be adequately applied in an academic setting, their vision and perspective is distinctive and valuable for re-assessing the current limitations of existing similarity and comparison models.
4: Conclusions and Recommendations
Conclusions
As higher educational institutes pursue a greater standard of accountability, the broad spectrum of plagiarism detection mechanisms, increasingly complex definition of plagiarism practises, and high degree of inconsistency in replicability and interpretation in analytical outputs is diluting the accuracy and adequacy of such measures.161 In fact, one of the most important elements that has yet to be adequately addressed in plagiarism research, theory, and practise is the function of semantic analysis and qualitative factors in the inconsistent capacity for dissecting student works. Past evidence in this field (See Youmans162 and Zeman et al.163) has demonstrated that there is a significant degree of variation in plagiarism outputs when assessing longitudinal evidence relating to multi-functional and multi-faceted writing assignments. Specifically, the likelihood of plagiarism by virtue of topic or level is increased according to the relative “difficulty’ of the subject or type of assignment in question. This degree of variability is an important consideration when assessing plagiarism monitoring and detection instruments, particularly when student enrolment and their continued higher education depends upon a passing output score on their university’s instrument of choice.
This research has demonstrated two primary dimensions of plagiarism monitoring and assessment: intrinsic and extrinsic. Focusing on grammaticality and linguistic relationships and voice, intrinsic plagiarism detection is quickly becoming a valuable mechanism for expedient, corpus-free monitoring of students’ work. Alternatively, the more traditional extrinsic model of plagiarism detection requires what has become a proprietary factor: a comprehensive database of comparative resources. Whilst the analytical approaches employed in each of these techniques may vary, their primary objectives do not: to identify passages or concepts which a student has plagiarised from an unreferenced source in an effort to present them as their own. Yet this objective itself is indicative of a fundamental conflict at the core of detection mechanisms as academics find that the identification and representation of intention is extremely difficult to qualify. Given that students have recognised the potential deficiencies of a copy-paste strategy in plagiarism obfuscation, new techniques focusing on intra-corporal manipulation and multi-language translation and manipulation are much more difficult to monitor and assess.
This research has provided a critical analysis of many different studies in this field, demonstrating a persistent focus on modelling and approach, whilst simultaneously failing to sufficiently address the core limitations and practical constraints of these multi-faceted models. With fuzzy analysis and semantic reasoning quickly becoming figureheads in more intuitive system design, it is evident from these findings that the nature of plagiarism detection is adapting in order to meet the challenge of subverting more complex student efforts. Seemingly, the foundations of plagiarism detection are based upon a stepwise progression, whereby the mechanisms of textual copying and manipulation are identified and then prevented as academics pursue the most comprehensive of monitoring resources. For students, the knowledge of more in-depth monitoring practises may act as a fundamental deterrent; however, it is evident that when faced with academic deviance and scholastic failure, deviance is likely to become an viable consideration.
Recommendations
The primary aim of this research was to assess the breadth of plagiarism monitoring and detection resources that are currently being employed in higher education institutions across the developed world. With globalised scholasticism a quickly evolving phenomenon, the scope of student ethics and value systems is magnified, requiring a much more definitive stance against plagiarism and its multiple iterations. For this reason, the findings in this analysis have revealed a continuum of student-oriented adaptations that are quickly altering the scope of monitoring and detection platforms. Accordingly, there are three primary dimensions of the effective plagiarism deterrence and detection system that have been extracted from this breadth of academic evidence. The following is a brief overview of this stepwise process which must consider both student and academic interests in its implementation:
- Education and Deterrence: Managing plagiarism in HEIs involves effective deterrence techniques. Whilst a zero tolerance policy is effective, it is evident from the findings of such researchers as Postle (2009)164 and Introna and Hayes (2011)165 that student decision making is oftentimes based upon concerns that are beyond the scope of policy constraints. Therefore, by instilling a robust sense of ethics, responsibility, and academic honour amongst the student population, it is more likely that the incidence of plagiarism will naturally decline.
- The Grey Area: One of the major challenges in anti-plagiarism policymaking is that conceptual and textual copying are frequently two different elements in student writing. Whilst a student might summarise and neglect a particular concept or idea, the ability to detect such offences is mitigated by the depth of analysis within the system itself. Conversely, the student might copy a published insight in an attempt to convey a robust idea or concept without attribution (due to oversight or otherwise honest mistakes). The challenge for educators is to determine what constitutes plagiarism and how can these standards be enforced universally. This grey area paradox may ultimately reflect in an intensified, formal rigidity which erroneously impacts upon the educational experience of ethically superior, honest students.
- Intrinsic Plagiarism Analysis: By starting with the student’s voice itself and leveraging a corpus of student work in the assessment of possible plagiarism, it becomes possible to statistically identify areas in which the student may have borrowed or taken ideas without appropriately sourcing the work of an outside author. The ability to assess student works on the basis of grammatical and semantic consistency is an important step forward in plagiarism detection and requires a much lower system demand that extrinsic, multi-database sourcing entails.
- Extrinsic, Semantic Plagiarism Analysis: Whilst most of the current service providers base their platform on extrinsic plagiarism detection, the underlying value of this approach is limited by the creativity and skill associated with modern student plagiarism. Therefore, the semantic, global thesaurus-based analysis of student works is likely to yield a much more accurate finding regarding the manipulation of language in order to copy or summarise the works of others. From multi-lingual to native language analysis, the broad spectrum of this analysis is likely to make detection complicated and require a comprehensive database (e.g. university resources including journals, books, etc.) that can span across multinational environments.
These three phases of plagiarism subversion, monitoring and detection are only a first stage in the analytical protocols that must be employed at the core of any university. With students continuing to engage in more subversive behaviour, the likelihood of eliminating plagiarism through any singular strategy is minimal. However, by broadening the scope of assessment, enhancing the depth of analysis, and re-focusing existing protocols on a more complex spectrum of dimensions, it is hypothesised that the incidence of plagiarism will begin to decrease over time.
References
1 Merriam Webster Dictionary, Definition of Plagiarize, (2012) https://www.merriam-webster.com/dictionary/plagiarize.
2 K. Dey and M.A. Sobhan, “Impact of Unethical Practices of Plagiarism on Learning, Teaching and Research in Higher Education: Some Combating Strategies,’ ITHET, (2006) pp. 1-6.
3 K. Dey and M.A. Sobhan, “Impact of Unethical Practices of Plagiarism on Learning, Teaching and Research in Higher Education: Some Combating Strategies,’ ITHET, (2006) p. 1.
4 K. Dey and M.A. Sobhan, “Impact of Unethical Practices of Plagiarism on Learning, Teaching and Research in Higher Education: Some Combating Strategies,’ ITHET, (2006).
5 S.M. Alzahrani, N. Salim, and A. Abraham. “Understanding Plagiarism Linguistic Patterns, Textual Features, and Detection Methods’ (2012), IEEE Transactions on Systems, Man, and Cybernetics: Part C, Vol. 42, No. 2, p. 134
6 S.M. Alzahrani, N. Salim, and A. Abraham. “Understanding Plagiarism Linguistic Patterns, Textual Features, and Detection Methods’ (2012), IEEE Transactions on Systems, Man, and Cybernetics: Part C, Vol. 42, No. 2, p. 134.
7 S.M. Alzahrani, N. Salim, and A. Abraham. “Understanding Plagiarism Linguistic Patterns, Textual Features, and Detection Methods’ (2012), IEEE Transactions on Systems, Man, and Cybernetics: Part C, Vol. 42, No. 2, p. 134.
8 S.M. Alzahrani, N. Salim, and A. Abraham. “Understanding Plagiarism Linguistic Patterns, Textual Features, and Detection Methods’ (2012), IEEE Transactions on Systems, Man, and Cybernetics: Part C, Vol. 42, No. 2, p. 134
9 K. Postle, “Detecting and Deterring Plagiarism in Social Work Students: Implications for Learning for Practice,’ (2009) Social Work Education, Vol. 28, No. 4, pp. 351-362.
10 K. Postle, “Detecting and Deterring Plagiarism in Social Work Students: Implications for Learning for Practice,’ (2009) Social Work Education, Vol. 28, No. 4, pp. 353-354.
11 L.D. Introna and N. Hayes “On Sociomaterial Imbrications: What Plagiarism Detection Systems Review and Why it Matters,’ (2011), pp. 107-122.
12 L.D. Introna and N. Hayes “On Sociomaterial Imbrications: What Plagiarism Detection Systems Review and Why it Matters,’ (2011), p. 117
13 B. Marsh, “Turnitin.com and the Scriptural Enterprise of Plagiarism Detection,’ (2004) Computers and Composition, Vol. 21, p. 429.
14 J. Compton and M. Pfau, “Inoculating Against Pro-Plagiarism Justifications: Rational and Affective Strategies,’ (2008) Journal of Applied Communication Research Vol. 36, No. 1, p. 115.
15 J. Compton and M. Pfau, “Inoculating Against Pro-Plagiarism Justifications: Rational and Affective Strategies,’ (2008) Journal of Applied Communication Research Vol. 36, No. 1, p. 115.
16 L. McKeever, “Online Plagiarism Detection Services—Saviour or Scourge?’ (2006) Assessment and Evaluation in Higher Education, Vol. 31, No. 2, pp. 155-165.
17 S.M. Alzahrani, N. Salim, and A. Abraham. “Understanding Plagiarism Linguistic Patterns, Textual Features, and Detection Methods’ (2012), IEEE Transactions on Systems, Man, and Cybernetics: Part C, Vol. 42, No. 2, p. 137.
18 S.M. Alzahrani, N. Salim, and A. Abraham. “Understanding Plagiarism Linguistic Patterns, Textual Features, and Detection Methods’ (2012), IEEE Transactions on Systems, Man, and Cybernetics: Part C, Vol. 42, No. 2, p. 137.
19 S.M. Alzahrani, N. Salim, and A. Abraham. “Understanding Plagiarism Linguistic Patterns, Textual Features, and Detection Methods’ (2012), IEEE Transactions on Systems, Man, and Cybernetics: Part C, Vol. 42, No. 2, p. 137.
20 G.R.S. Weir, M.A. Gordon, G. MacGregor. “Work in Progres—Technology in Plagiarism Detection and Management,’ (2004), IEEE Frontiers in Education Conference, pp.18-19.
21 G.R.S. Weir, M.A. Gordon, G. MacGregor. “Work in Progres—Technology in Plagiarism Detection and Management,’ (2004), IEEE Frontiers in Education Conference, p.19
22 G.R.S. Weir, M.A. Gordon, G. MacGregor. “Work in Progres—Technology in Plagiarism Detection and Management,’ (2004), IEEE Frontiers in Education Conference, p. 19
23 H. Zhang and T.W.S. Chow, “A Coarse to Fine Framework to Efficiently Thwart Plagiarism,’ (2011) Pattern Recognition, pp. 471-487.
24 H. Zhang and T.W.S. Chow, “A Coarse to Fine Framework to Efficiently Thwart Plagiarism,’ (2011) Pattern Recognition, pp.. 471-2.
25 H. Zhang and T.W.S. Chow, “A Coarse to Fine Framework to Efficiently Thwart Plagiarism,’ (2011) Pattern Recognition, pp. 475
26 Alzahrani et al., (2012)
27 J.D. Hill and E.F. Page, “An Empirical Research Study of the Efficacy of Two Plagiarism-Detection Applications,’ (2009) Journal of Web Librarianship, Vol. 3, No. 3, pp. 169-181.
28J.D. Hill and E.F. Page, “An Empirical Research Study of the Efficacy of Two Plagiarism-Detection Applications,’ (2009) Journal of Web Librarianship, Vol. 3, No. 3, p. 179.
29 J.D. Hill and E.F. Page, “An Empirical Research Study of the Efficacy of Two Plagiarism-Detection Applications,’ (2009) Journal of Web Librarianship, Vol. 3, No. 3, p.179.
30 S.M. Alzahrani, N. Salim, and A. Abraham. “Understanding Plagiarism Linguistic Patterns, Textual Features, and Detection Methods’ (2012), IEEE Transactions on Systems, Man, and Cybernetics: Part C, Vol. 42, No. 2, p. 137.
31 K.R. Rao. “Plagiarism a Scourge.’ Current Science, Vol. 94, No. 5, pp. 581-586.
32 R.J. Youmans, “Does the Adoption of Plagiarism-Detection Software in Higher Education Reduce Plagiarism?’ (2011) Studies in Higher Education, Vol. 36, No. 7, pp. 749-761.
33 L.D. Zeman, J.A. Steen, and N.M. Zeman, “Originality Detection Software in a Graduate Policy Course: A Mixed Methods Evaluation of Plagiarism,’ Journal of Teaching in Social Work, Vol. 31, No. 4, pp. 431-441.
34 N. Samuel, N. Samuel, and S. Butakov, “XML Based Format for Exchange of Plagiarism Detection Results,’ (2010) IEEE Information Science and Applications Conference, pp. 1-6.
35 N. Samuel, N. Samuel, and S. Butakov, “XML Based Format for Exchange of Plagiarism Detection Results,’ (2010) IEEE Information Science and Applications Conference, p. 1.
36 J. Heather, “Turnitoff: Identifying and Fixing a Hole in Current Plagiarism Detection Software,’ (2010) Assessment and Evaluation in Higher Education, Vol. 35, No. 6, p. 648.
37 J. Heather, “Turnitoff: Identifying and Fixing a Hole in Current Plagiarism Detection Software,’ (2010) Assessment and Evaluation in Higher Education, Vol. 35, No. 6, pp. 649-50.
38 J. Heather, “Turnitoff: Identifying and Fixing a Hole in Current Plagiarism Detection Software,’ (2010) Assessment and Evaluation in Higher Education, Vol. 35, No. 6, p. 649.
39 J. Heather, “Turnitoff: Identifying and Fixing a Hole in Current Plagiarism Detection Software,’ (2010) Assessment and Evaluation in Higher Education, Vol. 35, No. 6, p. 650.
40 J. Heather, “Turnitoff: Identifying and Fixing a Hole in Current Plagiarism Detection Software,’ (2010) Assessment and Evaluation in Higher Education, Vol. 35, No. 6, p. 650.
41 J. Heather, “Turnitoff: Identifying and Fixing a Hole in Current Plagiarism Detection Software,’ (2010) Assessment and Evaluation in Higher Education, Vol. 35, No. 6, pp. 651-2.
42 J. Heather, “Turnitoff: Identifying and Fixing a Hole in Current Plagiarism Detection Software,’ (2010) Assessment and Evaluation in Higher Education, Vol. 35, No. 6, p. 652-3.
43 J. Heather, “Turnitoff: Identifying and Fixing a Hole in Current Plagiarism Detection Software,’ (2010) Assessment and Evaluation in Higher Education, Vol. 35, No. 6, p. 657.
44 J. Heather, “Turnitoff: Identifying and Fixing a Hole in Current Plagiarism Detection Software,’ (2010) Assessment and Evaluation in Higher Education, Vol. 35, No. 6, p. 657.
45 J. Heather, “Turnitoff: Identifying and Fixing a Hole in Current Plagiarism Detection Software,’ (2010) Assessment and Evaluation in Higher Education, Vol. 35, No. 6, p. 658.
46 L.D. Introna and N. Hayes “On Sociomaterial Imbrications: What Plagiarism Detection Systems Review and Why it Matters,’ (2011).
47 K. Dey and M.A. Sobhan, “Impact of Unethical Practices of Plagiarism on Learning, Teaching and Research in Higher Education: Some Combating Strategies,’ ITHET, (2006) p. 2
48 C.K. Ryu, H.J. Kim, S.H. Ji, G. Woo, and H.G. Cho, “Detecting and Tracing Plagiarized Documents by Reconstruction Plagiarism Evolution Tree.’ IEEE: Proceedings of the 2009 ACM Symposium on Applied Computing, (2009), pp. 119-121.
49 C.K. Ryu, H.J. Kim, S.H. Ji, G. Woo, and H.G. Cho, “Detecting and Tracing Plagiarized Documents by Reconstruction Plagiarism Evolution Tree.’ IEEE: Proceedings of the 2009 ACM Symposium on Applied Computing, (2009), p. 121.
50 C.K. Ryu, H.J. Kim, S.H. Ji, G. Woo, and H.G. Cho, “Detecting and Tracing Plagiarized Documents by Reconstruction Plagiarism Evolution Tree.’ IEEE: Proceedings of the 2009 ACM Symposium on Applied Computing, (2009), p. 122.
51 C.K. Ryu, H.J. Kim, S.H. Ji, G. Woo, and H.G. Cho, “Detecting and Tracing Plagiarized Documents by Reconstruction Plagiarism Evolution Tree.’ IEEE: Proceedings of the 2009 ACM Symposium on Applied Computing, (2009), p. 122.
52 L.D. Introna and N. Hayes “On Sociomaterial Imbrications: What Plagiarism Detection Systems Review and Why it Matters,’ (2011), p. 114.
53 L.D. Introna and N. Hayes “On Sociomaterial Imbrications: What Plagiarism Detection Systems Review and Why it Matters,’ (2011), p. 114.
54 M. Zini, M. Fabbri, M. Moneglia, and A. Panunzi, “Plagiarism Detection Through Multilevel Text Comparison,’ IEEE: Proceedings of the Second International Conference on Automated Production of Cross Media Content for Multi-Channel Distribution, pp. 1-5
55 M. Zini, M. Fabbri, M. Moneglia, and A. Panunzi, “Plagiarism Detection Through Multilevel Text Comparison,’ IEEE: Proceedings of the Second International Conference on Automated Production of Cross Media Content for Multi-Channel Distribution, p. 3.
56 S. Butakov and V. Schcherbin, “On the Number of Search Queries Required for Internet Plagiarism Detection,’ IEEE: Ninth International Conference on Advanced Learning Technologies, (2009), pp. 482-483.
57 A. Knight, K. Almeroth, and B. Bimber, “An Automated System for Plagiarism Detection Using the Internet.’ In: L. Cantoni and C. McLoughlin (Eds.) Proceedings of the World Conference on Educational Multimedia, Hypermedia, and Telecommunications (2004), pp. 3619-3625.
58 A. Knight, K. Almeroth, and B. Bimber, “An Automated System for Plagiarism Detection Using the Internet.’ In: L. Cantoni and C. McLoughlin (Eds.) Proceedings of the World Conference on Educational Multimedia, Hypermedia, and Telecommunications (2004), 482.
59 A. Knight, K. Almeroth, and B. Bimber, “An Automated System for Plagiarism Detection Using the Internet.’ In: L. Cantoni and C. McLoughlin (Eds.) Proceedings of the World Conference on Educational Multimedia, Hypermedia, and Telecommunications (2004), 482.
60 F. Sanchez-Vega, E. Villatoro-Telo, M. Montes-y-Gomez, L. Villasenor-Pineda, and P. Rosso, “Determining and Characterizing the Reused Text for Plagiarism Detection,’ (2012) Expert Systems With Applications, p, 1
61 F. Sanchez-Vega, E. Villatoro-Telo, M. Montes-y-Gomez, L. Villasenor-Pineda, and P. Rosso, “Determining and Characterizing the Reused Text for Plagiarism Detection,’ (2012) Expert Systems With Applications, p. 2.
62 F. Sanchez-Vega, E. Villatoro-Telo, M. Montes-y-Gomez, L. Villasenor-Pineda, and P. Rosso, “Determining and Characterizing the Reused Text for Plagiarism Detection,’ (2012) Expert Systems With Applications, p. 4.
63 F. Sanchez-Vega, E. Villatoro-Telo, M. Montes-y-Gomez, L. Villasenor-Pineda, and P. Rosso, “Determining and Characterizing the Reused Text for Plagiarism Detection,’ (2012) Expert Systems With Applications, p. 9.
64 C.K. Kent and N. Salim, “Web Based Cross Language Semantic Plagiarism Detection’, IEEE 9th International Conference on Dependable, Automatic, and Secure Computing, (2011), pp. 1096-1102.
65 S. Alzahrani, M.S. Binwahlan, N. Salim, L. Sunmali, and C.K. Kent, “The Development of Cross-Language Plagiarism Detection Tool Utilising Fuzzy Swarm-Based Summarisation.’ IEEE: 10th International Conference on Intelligent Systems Design and Applications, pp. 86-90
66 Y.Li, D. McLean, Z.A. Bandar, J.D. O’Shea, and K. Crockett.’ Sentence Similarity Based on Sematic Nets and Corpus Statistics.’ IEEE Knowledge and Data Engineering, (2006), Vol. 18, No .8.
67 Y.Li, D. McLean, Z.A. Bandar, J.D. O’Shea, and K. Crockett.’ Sentence Similarity Based on Sematic Nets and Corpus Statistics.’ IEEE Knowledge and Data Engineering, (2006), Vol. 18, No .8,
p. 1142.
68 WordNet, “What is WordNet?’ (2012), Online Resource. Accessed on 10th November From: https://wordnet.princeton.edu/.
69 Y.Li, D. McLean, Z.A. Bandar, J.D. O’Shea, and K. Crockett.’ Sentence Similarity Based on Sematic Nets and Corpus Statistics.’ IEEE Knowledge and Data Engineering, (2006), Vol. 18, No .8, p. 1144.
70 Y.Li, D. McLean, Z.A. Bandar, J.D. O’Shea, and K. Crockett.’ Sentence Similarity Based on Sematic Nets and Corpus Statistics.’ IEEE Knowledge and Data Engineering, (2006), Vol. 18, No .8, p. 1148.
71 Z. Ceska, “Plagiarism Detection Based on Singular Value Decomposition,’ In: A. Ranta and B. Nortstrom (Eds) Advances in Natural Language Processing, (2008).
72 Z. Ceska, “Plagiarism Detection Based on Singular Value Decomposition,’ In: A. Ranta and B. Nortstrom (Eds) Advances in Natural Language Processing, (2008), pp. 110-14.
73 D. Ceglarek and K. Haniewicz, “Fast Plagiarism Detection by Sentence Hashing,’ In: L. Rutkowski et al. (Eds.), Artificial Intelligence and Soft Computing, (2012), p. 30
74 D. Ceglarek and K. Haniewicz, “Fast Plagiarism Detection by Sentence Hashing,’ In: L. Rutkowski et al. (Eds.), Artificial Intelligence and Soft Computing, (2012), p. 31
75 D. Ceglarek and K. Haniewicz, “Fast Plagiarism Detection by Sentence Hashing,’ In: L. Rutkowski et al. (Eds.), Artificial Intelligence and Soft Computing, (2012), p. 32
76 D. Ceglarek and K. Haniewicz, “Fast Plagiarism Detection by Sentence Hashing,’ In: L. Rutkowski et al. (Eds.), Artificial Intelligence and Soft Computing, (2012), p. 35
77 Z. Xiaoping, M. Xiaoxuan, and S. Honghong, “Research on a VSM-Based E-Homework Anti Plagiarism System,’ IEEE International Conference on Information Management, Innovation Management, and Industrial Engineering, (2012), 102-105.
78 N. Samuel, N. Samuel, and S. Butakov, “XML Based Format for Exchange of Plagiarism Detection Results,’ (2010) IEEE Information Science and Applications Conference, pp. 1-6.
79 N. Samuel, N. Samuel, and S. Butakov, “XML Based Format for Exchange of Plagiarism Detection Results,’ (2010) IEEE Information Science and Applications Conference, p. 5.
80 K. Dey and M.A. Sobhan, “Impact of Unethical Practices of Plagiarism on Learning, Teaching and Research in Higher Education: Some Combating Strategies,’ ITHET, (2006).
81 M. Tschuggnall and G. Specht, “Plag-Inn: Intrinsic Plagiarism Detection Using Grammar Trees,’ In: Bouma et al. (Eds.). NLDB, (2012), p. 284.
82 M. Tschuggnall and G. Specht, “Plag-Inn: Intrinsic Plagiarism Detection Using Grammar Trees,’ In: Bouma et al. (Eds.). NLDB, (2012), p. 285
83 M. Tschuggnall and G. Specht, “Plag-Inn: Intrinsic Plagiarism Detection Using Grammar Trees,’ In: Bouma et al. (Eds.). NLDB, (2012), p. 285.
84 S. Myer zu Eissen and B. Stein, “Intrinsic Plagiarism Detection,’ M. Lalmas et al. (Eds). ECIR, (2006), pp. 565-569.
85 S. Myer zu Eissen and B. Stein, “Intrinsic Plagiarism Detection,’ M. Lalmas et al. (Eds). ECIR, (2006), p. 566-7.
86 S. Myer zu Eissen and B. Stein, “Intrinsic Plagiarism Detection,’ M. Lalmas et al. (Eds). ECIR, (2006), p. 567.
87 S. Myer zu Eissen and B. Stein, “Intrinsic Plagiarism Detection,’ M. Lalmas et al. (Eds). ECIR, (2006), p. 567
88 S. Sandhya and S. Chitrakala, “Plagiarism Detection of Paraphrases in Text Documents with Document Retrieval,’ In: Advances in Computing and Information Technology Vol. 198, pp. 330-338.
89 S. Sandhya and S. Chitrakala, “Plagiarism Detection of Paraphrases in Text Documents with Document Retrieval,’ In: Advances in Computing and Information Technology Vol. 198, p. 332.
90 S. Sandhya and S. Chitrakala, “Plagiarism Detection of Paraphrases in Text Documents with Document Retrieval,’ In: Advances in Computing and Information Technology Vol. 198, p. 332.
91 D. Micol, O. Ferrandez, and R. Munoz, “Information Retrieval Techniques for Corpus Filtering Applied to External Plagiarism Detection,’ In: R. Munoz et al. (Eds) NLDB, (2011), p. 101.
92 D. Micol, O. Ferrandez, and R. Munoz, “Information Retrieval Techniques for Corpus Filtering Applied to External Plagiarism Detection,’ In: R. Munoz et al. (Eds) NLDB, (2011), p. 102-3
93 D. Micol, O. Ferrandez, and R. Munoz, “Information Retrieval Techniques for Corpus Filtering Applied to External Plagiarism Detection,’ In: R. Munoz et al. (Eds) NLDB, (2011), p. 109.
94 G. Oberreuter, G. L’Hullier, S.A. Rios, and J.D. Velasquez, “Outlier-Based Approaches for Intrinsic and External Plagiarism Detection,’ In: A. Konig et al. (Eds)., KES, pp. 11-20.
95 G. Oberreuter, G. L’Hullier, S.A. Rios, and J.D. Velasquez, “Outlier-Based Approaches for Intrinsic and External Plagiarism Detection,’ In: A. Konig et al. (Eds)., KES, p. 12
96 G. Oberreuter, G. L’Hullier, S.A. Rios, and J.D. Velasquez, “Outlier-Based Approaches for Intrinsic and External Plagiarism Detection,’ In: A. Konig et al. (Eds)., KES, p. 12
97 E. Stamatatos, “Intrinsic Plagiarism Detection Using Character n-Gram Profiles.’ In: B. Stein, P. Rosso, E. Stamatatos, M. Koppel, and E. Agirre, (Eds). SEPLN, (2009), pp. 38-46.
98 G. Oberreuter, G. L’Hullier, S.A. Rios, and J.D. Velasquez, “Outlier-Based Approaches for Intrinsic and External Plagiarism Detection,’ In: A. Konig et al. (Eds)., KES, p. 14.
99 T. Suzuki, S. Kawamura, F. Yoshikane, K. Kageura, and A. Aizawa, “Co-Occurrence Based Indicators for Authorship Analysis’, Literary and Linguistic Computing, (2012), Vol. 27, No. 2, pp. 197-214.
100 T. Suzuki, S. Kawamura, F. Yoshikane, K. Kageura, and A. Aizawa, “Co-Occurrence Based Indicators for Authorship Analysis’, Literary and Linguistic Computing, (2012), Vol. 27, No. 2, p. 199.
101 T. Suzuki, S. Kawamura, F. Yoshikane, K. Kageura, and A. Aizawa, “Co-Occurrence Based Indicators for Authorship Analysis’, Literary and Linguistic Computing, (2012), Vol. 27, No. 2, p. 210.
102 A.H. Osman, N. Salim, Y.J. Kumar, and A. Abuobieda, “Fuzzy Semantic Plagiarism Detection,’ In: E. Hassanien et al. (Eds) Advanced Machine Learning Technologies and Applications, Vol. 332, pp. 543-553.
103 A.H. Osman, N. Salim, Y.J. Kumar, and A. Abuobieda, “Fuzzy Semantic Plagiarism Detection,’ In: E. Hassanien et al. (Eds) Advanced Machine Learning Technologies and Applications, Vol. 332, p. 546
104 A.H. Osman, N. Salim, Y.J. Kumar, and A. Abuobieda, “Fuzzy Semantic Plagiarism Detection,’ In: E. Hassanien et al. (Eds) Advanced Machine Learning Technologies and Applications, Vol. 332, p. 547
105 A.H. Osman, N. Salim, Y.J. Kumar, and A. Abuobieda, “Fuzzy Semantic Plagiarism Detection,’ In: E. Hassanien et al. (Eds) Advanced Machine Learning Technologies and Applications, Vol. 332, p. 552
106 P. Foudeh and N. Salim. “A Holistic Approach to Duplicate Publication and Plagiarism Detection Using Probabilistic Ontologies.’ In: E. Hassanien et al. (Eds) Advanced Machine Learning Technologies and Applications, Vol. 332, pp. 566-574.
107 P. Foudeh and N. Salim. “A Holistic Approach to Duplicate Publication and Plagiarism Detection Using Probabilistic Ontologies.’ In: E. Hassanien et al. (Eds) Advanced Machine Learning Technologies and Applications, Vol. 332, p. 573.
108 K. Dey and M.A. Sobhan, “Impact of Unethical Practices of Plagiarism on Learning, Teaching and Research in Higher Education: Some Combating Strategies,’ ITHET, (2006) p. 2
109 G.R.S. Weir, M.A. Gordon, G. MacGregor. “Work in Progres—Technology in Plagiarism Detection and Management,’ (2004), IEEE Frontiers in Education Conference, p. 18.
110 G.R.S. Weir, M.A. Gordon, G. MacGregor. “Work in Progres—Technology in Plagiarism Detection and Management,’ (2004), IEEE Frontiers in Education Conference, p. 19.
111 G.R.S. Weir, M.A. Gordon, G. MacGregor. “Work in Progres—Technology in Plagiarism Detection and Management,’ (2004), IEEE Frontiers in Education Conference, p. 19.
112 O.H. Graven and L.M. MacKinnon, “A Consideration of the Use of Plagiarism Tools for Automated Student Assessment’, IEEE Transactions on Education, Vol. 51, No. 2, pp. 212-220.
113 O.H. Graven and L.M. MacKinnon, “A Consideration of the Use of Plagiarism Tools for Automated Student Assessment’, IEEE Transactions on Education, Vol. 51, No. 2, p. 219.
114 S. Alzahrani, M.S. Binwahlan, N. Salim, L. Sunmali, and C.K. Kent, “The Development of Cross-Language Plagiarism Detection Tool Utilising Fuzzy Swarm-Based Summarisation.'(2010) IEEE: 10th International Conference on Intelligent Systems Design and Applications, pp. 86-90
115 S. Alzahrani, M.S. Binwahlan, N. Salim, L. Sunmali, and C.K. Kent, “The Development of Cross-Language Plagiarism Detection Tool Utilising Fuzzy Swarm-Based Summarisation.'(2010) IEEE: 10th International Conference on Intelligent Systems Design and Applications, p. 86.
116 S. Alzahrani, M.S. Binwahlan, N. Salim, L. Sunmali, and C.K. Kent, “The Development of Cross-Language Plagiarism Detection Tool Utilising Fuzzy Swarm-Based Summarisation.'(2010) IEEE: 10th International Conference on Intelligent Systems Design and Applications, p. 88.
117 Google. “Google Translate API.’ (2012), Online Resource. Accessed on 10th November From: https://developers.google.com/translate/.
118 Google. “Google Translate API.’ (2012), Online Resource. Accessed on 10th November From: https://developers.google.com/translate/.
119 S. Alzahrani, M.S. Binwahlan, N. Salim, L. Sunmali, and C.K. Kent, “The Development of Cross-Language Plagiarism Detection Tool Utilising Fuzzy Swarm-Based Summarisation.’ (2010) IEEE: 10th International Conference on Intelligent Systems Design and Applications, p. 89.
120 D. Pecorari, “Good and Original: Plagiarism and Patchwriting in Academic Second-Language Writing,'(2003) Journal of Second Language Writing, Vol. 12, pp. 317-345.
121 P. Stapleton, “Gauging the Effectiveness of Anti-Plagiarism Software: An Empirical Study of Second Language Graduate Writers,’ (2012) Journal of English for Academic Purposes, Vol. 11, pp. 125-133.
122 P. Stapleton, “Gauging the Effectiveness of Anti-Plagiarism Software: An Empirical Study of Second Language Graduate Writers,’ (2012) Journal of English for Academic Purposes, Vol. 11, p. 130.
123 P. Stapleton, “Gauging the Effectiveness of Anti-Plagiarism Software: An Empirical Study of Second Language Graduate Writers,’ (2012) Journal of English for Academic Purposes, Vol. 11, p. 132.
124 Z. Ceska, M. Toma, and K. Jezek, “Multilingual Plagiarism Detection,’ In: D. Dochev, M. Pistore, and P. Traverso (Eds) AMISA (2008), pp. 83-92.
125 Z. Ceska, M. Toma, and K. Jezek, “Multilingual Plagiarism Detection,’ In: D. Dochev, M. Pistore, and P. Traverso (Eds) AMISA (2008), p. 84
126 Z. Ceska, M. Toma, and K. Jezek, “Multilingual Plagiarism Detection,’ In: D. Dochev, M. Pistore, and P. Traverso (Eds) AMISA (2008), p. 85
127 C. Sowden, “Plagiarism and the Culture of Multilingual Students in Higher Education Abroad,’ ELT Journal, (2005), p. 226.
128 C. Sowden, “Plagiarism and the Culture of Multilingual Students in Higher Education Abroad,’ ELT Journal, (2005), p. 228.
129 C. Sowden, “Plagiarism and the Culture of Multilingual Students in Higher Education Abroad,’ ELT Journal, (2005), p. 228-30.
130 P.L. Ha, “Plagiarism and Overseas Students: Stereotypes Again?’ ELT Journal, (2006), pp. 76-78.
131 P.L. Ha, “Plagiarism and Overseas Students: Stereotypes Again?’ ELT Journal, (2006), p. 78.
132 D. Liu, “Plagiarism in ESOL Students: Is Cultural Conditioning Truly the Major Culprit?’ ELT Journal, (2005), pp. 234-241.
133 D. Liu, “Plagiarism in ESOL Students: Is Cultural Conditioning Truly the Major Culprit?’ ELT Journal, (2005), p. 241.
134 C.K Kent and N. Salim, “Web Based Cross Language Plagiarism Detection,’ IEEE ICCIMS, Vol. 2, pp. 199-204.
135 C.K Kent and N. Salim, “Web Based Cross Language Plagiarism Detection,’ IEEE ICCIMS, Vol. 2.
136 C.K. Kent and N. Salim, “Web Based Cross Language Semantic Plagiarism Detection,’ IEEE ICDASC, Vol. 9, p. 1098.
137 C.K. Kent and N. Salim, “Web Based Cross Language Semantic Plagiarism Detection,’ IEEE ICDASC, Vol. 9, p. 1098.
138 C.K. Kent and N. Salim, “Web Based Cross Language Semantic Plagiarism Detection,’ IEEE ICDASC, Vol. 9, p. 1098.
139 C.K. Kent and N. Salim, “Web Based Cross Language Semantic Plagiarism Detection,’ IEEE ICDASC, Vol. 9, p. 1098.
140 C.K. Kent and N. Salim, “Web Based Cross Language Semantic Plagiarism Detection,’ IEEE ICDASC, Vol. 9, p. 1100.
141 C.K. Kent and N. Salim, “Web Based Cross Language Semantic Plagiarism Detection,’ IEEE ICDASC, Vol. 9, p. 1101.
142 C.K. Kent and N. Salim, “Web Based Cross Language Semantic Plagiarism Detection,’ IEEE ICDASC, Vol. 9, p. 1101.
143 V.G. Kaburlasos, L. Moussiades, and A. Vakali, “Fuzzy Lattice Reasoning (FLR) Type Neural Computation for Weighted Graph Partitioning,’ Neurocomputing, Vol. 72.
144 V.G. Kaburlasos, L. Moussiades, and A. Vakali, “Fuzzy Lattice Reasoning (FLR) Type Neural Computation for Weighted Graph Partitioning,’ Neurocomputing, Vol. 72, p. 2124.
145 R.M. Alguliev, R.M. Alguliyev, and C.A. Mehdiyev, “Sentence Selection for Generic Document Summarization Using an Adaptive Differential Evolution Algorithm,’ Swarm and Evolutionary Computation, Vol. 1, p. 215
146 R.M. Alguliev, R.M. Alguliyev, and C.A. Mehdiyev, “Sentence Selection for Generic Document Summarization Using an Adaptive Differential Evolution Algorithm,’ Swarm and Evolutionary Computation, Vol. 1, p. 221
147 M.S. Binwahlan, N. Salim, and L. Suanmali, “Fuzzy Swarm Diversity Hybrid Model for Text Summarization,’ Information Processing and Management, Vol. 46, pp. 571-588.
148 M.S. Binwahlan, N. Salim, and L. Suanmali, “Fuzzy Swarm Diversity Hybrid Model for Text Summarization,’ Information Processing and Management, Vol. 46, p. 572.
149 M.S. Binwahlan, N. Salim, and L. Suanmali, “Fuzzy Swarm Diversity Hybrid Model for Text Summarization,’ Information Processing and Management, Vol. 46, p. 574.
150 M.S. Binwahlan, N. Salim, and L. Suanmali, “Fuzzy Swarm Diversity Hybrid Model for Text Summarization,’ Information Processing and Management, Vol. 46, p. 578.
151 M.S. Binwahlan, N. Salim, and L. Suanmali, “Fuzzy Swarm Diversity Hybrid Model for Text Summarization,’ Information Processing and Management, Vol. 46, p. 581.
152 M.S. Binwahlan, N. Salim, and L. Suanmali, “Fuzzy Swarm Diversity Hybrid Model for Text Summarization,’ Information Processing and Management, Vol. 46, p. 583.
153 R. M. Alguliev, R.M. Aliguliyev, M.S. Hajirahimova, and C.A. Mehdiyev, “MCMR: Maximum Coverage and Minimum Redundant Text Summarization Model,’ Expert Systems With Applications, Vol. 38, pp. 14514-14522.
154 R. M. Alguliev, R.M. Aliguliyev, M.S. Hajirahimova, and C.A. Mehdiyev, “MCMR: Maximum Coverage and Minimum Redundant Text Summarization Model,’ Expert Systems With Applications, Vol. 38.
155 R. M. Alguliev, R.M. Aliguliyev, M.S. Hajirahimova, and C.A. Mehdiyev, “MCMR: Maximum Coverage and Minimum Redundant Text Summarization Model,’ Expert Systems With Applications, Vol. 38, p. 14516.
156 R. M. Alguliev, R.M. Aliguliyev, M.S. Hajirahimova, and C.A. Mehdiyev, “MCMR: Maximum Coverage and Minimum Redundant Text Summarization Model,’ Expert Systems With Applications, Vol. 38, p. 14518.
157 M.S. Yang, W.L. Hung, and D.H. Chen, “Self-Organizing Map for Symbolic Data,’ Fuzzy Sets and Systems, Vol. 203.
158 M.S. Yang, W.L. Hung, and D.H. Chen, “Self-Organizing Map for Symbolic Data,’ Fuzzy Sets and Systems, Vol. 203, p. 49
159 M.S. Yang, W.L. Hung, and D.H. Chen, “Self-Organizing Map for Symbolic Data,’ Fuzzy Sets and Systems, Vol. 203, p. 51-2.
160 M.S. Yang, W.L. Hung, and D.H. Chen, “Self-Organizing Map for Symbolic Data,’ Fuzzy Sets and Systems, Vol. 203, p. 72.
161 K. Postle, “Detecting and Deterring Plagiarism in Social Work Students: Implications for Learning for Practice,’ (2009) Social Work Education, Vol. 28, No. 4, p. 358.
162 R.J. Youmans, “Does the Adoption of Plagiarism-Detection Software in Higher Education Reduce Plagiarism?’ (2011) Studies in Higher Education, Vol. 36, No. 7, p. 760.
163 L.D. Zeman, J.A. Steen, and N.M. Zeman, “Originality Detection Software in a Graduate Policy Course: A Mixed Methods Evaluation of Plagiarism,’ Journal of Teaching in Social Work, Vol. 31, No. 4, p. 439.
164 K. Postle, “Detecting and Deterring Plagiarism in Social Work Students: Implications for Learning for Practice,’ (2009) Social Work Education, Vol. 28, No. 4.
165 L.D. Introna and N. Hayes “On Sociomaterial Imbrications: What Plagiarism Detection Systems Review and Why it Matters,’ (2011).